
Rhizome: an LLM-maintained personal wiki
A Python CLI plus a native macOS menu-bar companion that turns raw sources into a persistent, cross-linked Obsidian vault — an LLM-Wiki that the model maintains rather than re-derives at every query.
Rhizome is an LLM-maintained personal wiki: a Python CLI plus a native macOS menu-bar companion that turns raw sources (PDFs, web pages, Notion exports, stray markdown) into a persistent, cross-linked Obsidian vault. It implements the LLM Wiki pattern proposed by Andrej Karpathy: a compounding markdown knowledge base that the LLM maintains rather than re-derives at every query. The result is a 23k-line two-language codebase with 500+ tests and a shippable Mac app.
The brief.
Rhizome targets a specific user: the deep-research individual — the academic, analyst, lifelong learner, or technically-fluent knowledge worker who already runs a local Obsidian vault and feels the maintenance burden of personal knowledge management (PKM). Tiago Forte calls the goal a Second Brain: an external system to capture, organize, and resurface ideas. The real problem he identifies is not capture but upkeep — the tedious bookkeeping of updating cross-references, refreshing summaries, flagging contradictions, and keeping consistency across hundreds of notes. As Karpathy puts it, humans abandon wikis because the maintenance burden grows faster than the value.
The broader note-taking market is large but fragmented: estimates run between roughly $1.2 B and $17 B for 2025, with 11–22% CAGRs through 2034. Obsidian sits at 1–1.5 M active users and roughly 8% of the total note-taking market, but holds the leading position among power users and researchers. Rhizome is built around the hypothesis that a competent agentic LLM can absorb the maintenance burden — writing the wiki rather than just chatting on top of it.
Target: Deep-research individuals — academics, analysts, lifelong learners, and technically-fluent knowledge workers who already run a local Obsidian vault and feel its maintenance burden.
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.Karpathy, quoted in the write-up
The landscape.
| Tool | Approach | Weakness | Our edge |
|---|---|---|---|
| Cloud-AI knowledge tools (Notion AI, Mem, Reflect, Tana, Heptabase) | Polished AI features layered onto a proprietary, hosted database | Force migration into a proprietary store; none interoperate cleanly with an existing Obsidian vault; vendor lock-in is unavoidable | Rhizome is local-first and editor-agnostic — the vault is just plain markdown files that survive the product |
| Source-grounded chat (NotebookLM, ChatGPT file-uploads, Perplexity Spaces) | Strong retrieval against documents you upload | The LLM rediscovers knowledge from scratch on every question; nothing accumulates between sessions | Rhizome saves outputs back into the vault, so every query incrementally enriches the corpus |
| Obsidian AI plugins (Smart Connections, Copilot for Obsidian) | Add chat and embedding-based related-notes panels inside the Obsidian editor | Sidecars that augment reading; they do not write pages, restructure the vault, or file saved answers back into long-term memory | Rhizome ships a vocabulary (source / article / map / output) and slash commands that the LLM drives to do the upkeep itself |
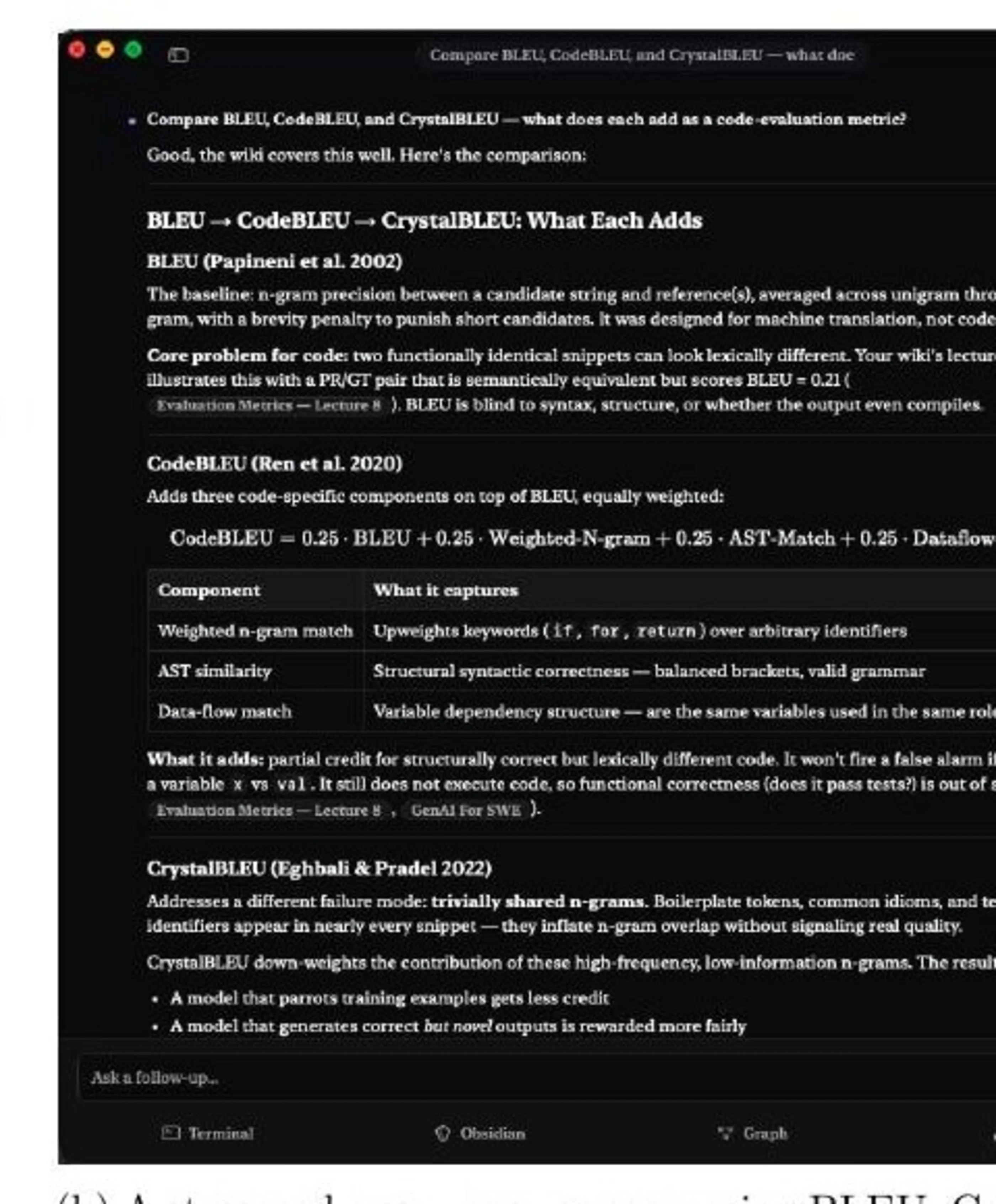
The core differentiator is architectural, not cosmetic, and it is shared with the LLM-Wiki pattern Karpathy described: a persistent, compounding markdown artifact maintained by the LLM, not a query-time RAG cache. Three concrete consequences follow. Compounding knowledge over re-retrieval: ingestion produces a permanent source note, and saved query outputs are filed back as wiki pages, so every question incrementally enriches the corpus. Local-first and editor-agnostic: the vault remains a normal Obsidian vault if Rhizome disappears tomorrow. Maintenance, not just chat: slash commands for query, capture, lint, and synthesis turn the model into a research assistant that writes the wiki versus a chat panel that reads it.
The system.
Rhizome is built as two layers over a shared template contract. The Python CLI (3.11+, built on Click, PyMuPDF, BeautifulSoup, and SQLite FTS5) is distributed as a wheel and bundled into the Mac app via PyInstaller; it owns deterministic vault operations — source-note assembly, vault read/write/search, synthesis-priority heuristics, output rendering (Marp decks, charts, canvases), a headless eval harness, and lint. The macOS menu-bar app is a SwiftUI app (Swift 6, macOS 14+) with WKWebView rendering of streamed markdown using bundled KaTeX, Mermaid, and DOMPurify; a core module encapsulates the headless logic (subprocess management, query session state, wiki search, wikilink parsing) and a UI shell provides the launcher, thread history, and answer renderer.
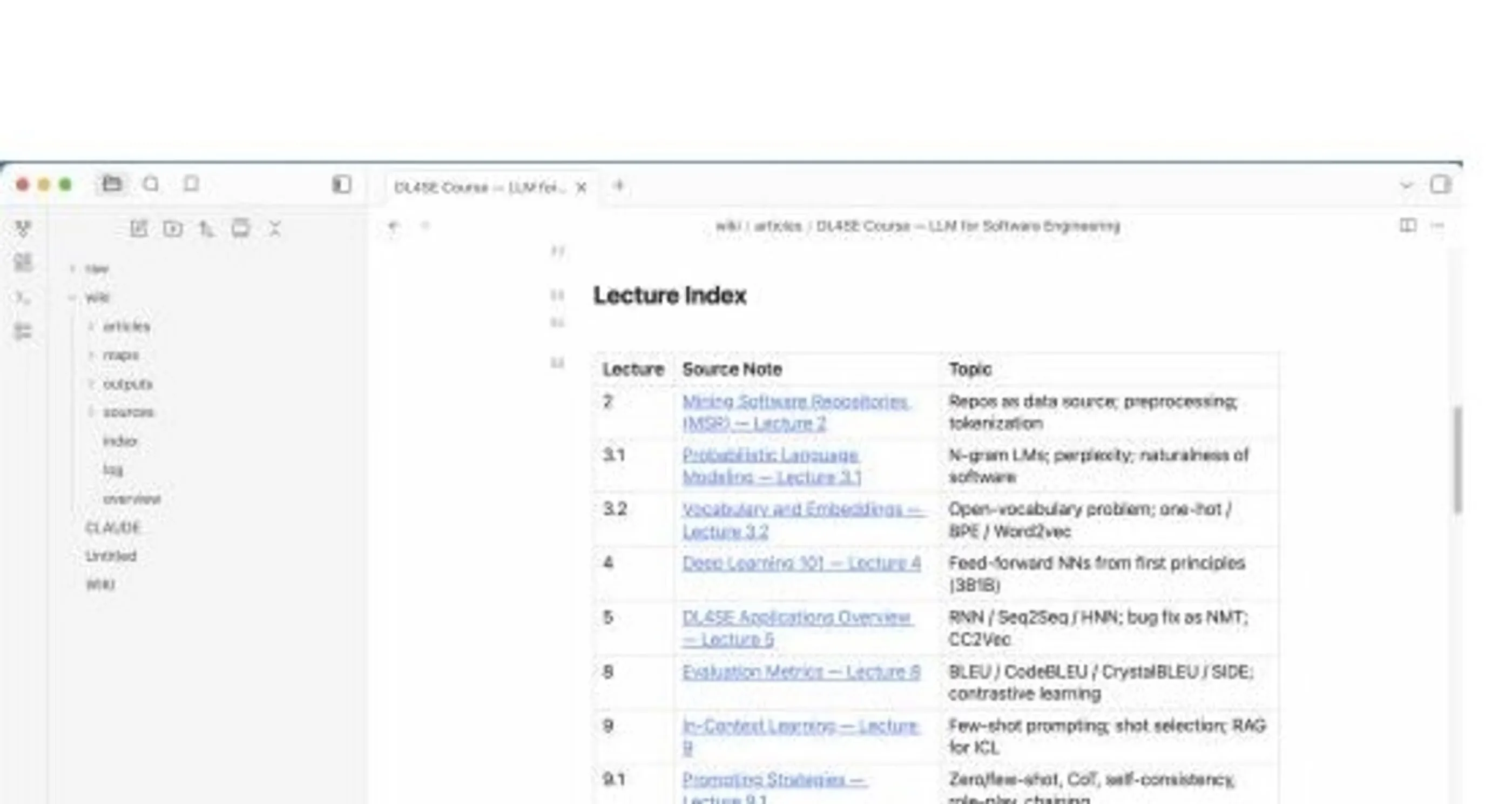
The product enforces three layers with one contract: raw/ holds immutable source documents (the LLM reads but never edits), wiki/ holds LLM-maintained markdown — every page is grounded in something in raw/ and is one of four types: source (one per raw file), article (cross-source synthesis), map (navigation hub), or output (saved answer / deck / chart / canvas). A workspace schema document tells the LLM how the vault is structured, what status levels mean, and how to link pages.
Ingest, query, lint/synthesis, and evals are the four operational modes. The CLI normalizes input (cached PDF page extraction, web fetch with optional image download) and emits a JSON event stream the Mac app surfaces in real time. The Mac app launches Claude Code as an agentic session against the workspace, with Bash/search/Task subagents allowed but direct edit/write tools blocked — Claude cites with [[wikilinks]] and only saves an output page on explicit user confirmation. Threads are resumable so follow-ups inherit context without re-priming.

The implementation.
Rhizome was built across Claude Code and Codex in long agentic sessions. The dominant pattern was adversarial review: a second agent (Codex when the working session was Claude, or vice versa) audited the working session's unstaged diffs, and the auditor's findings got pasted back in for the working agent to defend or revise. This caught behavior regressions in prompt and template edits that single-agent review missed — the working agent had no incentive to flag its own over-reach.
Two iteration patterns mattered most. First, rich-output prompting: the first workspace contract hedged with phrases like "only when clearly improves." Replacing those with a concrete trigger table (4+ concepts → canvas, 3+ items → table) materially changed the model's output. Hedge language was a permission slip; numeric triggers weren't. Second, agentic query reliability: Claude sometimes answered "this topic is not in your wiki" even when the note existed. An early fix prefetched deterministic context but undercut the goal of leveraging Claude's own search. The final design restored a Claude-led loop, opened the full set of search/execution tools, and required wiki search before any absence claim — which motivated shipping the eval harness so prompt edits became something to regression-test.
Both layers carry meaningful test coverage: 391 Python tests (pytest) plus 113 Swift tests (swift test) for a total of 504. The Python suites cover vault scan, search, upsert, and graph helpers that the query agent depends on; the Swift integration suite exercises the real Python sidecar across the JSON envelope boundary; smoke runs of init, setup, status, and health commands pass cleanly in a scratch directory.
Built with AI.
Where AI helped
- Whole modules drafted from a behavioral spec — the expected wins landed.
- Cross-language consistency between the Python sidecar and Swift JSON decoders held under refactor.
- Scaffolding for 504 tests across two languages held up under refactor pressure.
- Parallel research during ingest: Claude used multiple subagents concurrently to fetch sources — a case where agentic workflows actually created leverage.
Where AI struggled
- Scope creep — Claude kept reintroducing automatic figure extraction and source-packet flows the workspace contract explicitly forbids.
- End-to-end blindness — the Mac-app launch and in-app rendering bugs were both "green tests, broken product," with Claude declaring done against unit tests that never ran the real binary.
- Premature abstraction — a multi-query weighted ranking system grew inside the Obsidian connector, and the template installer was rewritten to use hard-coded allowlists instead of a directory scan, silently breaking new templates. The auditor agent caught both.
Hedge language is a permission slip — replacing "only when clearly improves" with numeric triggers was the single highest-leverage edit in the project. Prompts and schemas are product code: the workspace contract, schema document, and slash-command templates deserve the same review discipline as Swift or Python. Architectural decisions don't delegate — the page-type vocabulary, three-layer contract, and the boundary between deterministic CLI and interpretive Claude were all human calls. Claude executed them well but never proposed them well unprompted.
The evidence.
Limits & next.
Limits
- The eval harness covers a narrow slice (single-shot query prompts against a frozen workspace); it does not exercise PDF ingestion, save round-trips, or follow-up queries against saved pages.
- The current build is a developer-signed macOS bundle — Apple notarization and a non-CLI workspace creation flow are still required before a non-technical onboarding is realistic.
- Distribution today is a Python wheel installed via uv tool install plus an ad-hoc signed Mac bundle — not a one-click consumer install.
- The product depends on Claude Code as the agentic loop; portability to other agents is a future contract concern.
Next
- Expand the eval harness to cover ingest, save round-trips, and multi-turn follow-up queries — close the regression-diff loop end-to-end.
- Ship Apple notarization and automatic Obsidian/Claude Code setup so first launch is non-technical.
- Stand up the prosumer BYO-key tier ($8–12/mo) with hosted templates, sync, and a managed eval/lint service.
- Seed the Karpathy/LLM-Wiki and r/ObsidianMD communities with the architecture write-up and demo as SEO against 'LLM wiki' and 'second brain AI.'