
Multimodal Video Indexing
Replacing flawed metadata search with natural-language retrieval over short-form video, powered by a locally-hosted multimodal LLM.
Short-form video lacks searchable metadata, relying on user-supplied captions or tags. The team builds a minimal video platform powered by a localized multimodal pipeline that enables natural-language search of short-form videos. The pipeline runs Qwen2.5-Omni 7B locally to auto-generate text descriptions from synchronized audio and visual streams, then indexes those descriptions in Elasticsearch. One-shot prompting lets a 7B model recognize specific entities typically reserved for 30B+ models.
The brief.
Short-form video on TikTok, Instagram Reels, and YouTube Shorts is discoverable almost entirely through user-generated captions, hashtags, and creator account names. That metadata is subjective, spam-prone, and frequently fails to describe the actual visual and auditory events inside the clip. When a user remembers a specific quote or a visual moment but does not know the exact user-supplied tags, retrieving the video becomes nearly impossible.
A resource-efficient multimodal pipeline closes the gap. By running Qwen2.5-Omni 7B locally inside a 16GB RAM constraint and synchronizing tokens from audio and video via Time-aligned Multimodal RoPE, the platform produces structured textual summaries that an Elasticsearch index can serve as natural-language search results — without sending sensitive video to a third-party cloud.
Target: Niche social-media platforms, internal enterprise asset managers, and smaller creator-economy startups that need automated metadata enrichment for private or localized video repositories.
This technical efficiency ensures that our platform remains responsive and scalable on local infrastructure, bypassing the latency and data-privacy concerns associated with sending sensitive video data to third-party cloud providers.From the write-up
The landscape.
| Tool | Approach | Weakness | Our edge |
|---|---|---|---|
| Google Cloud Video AI | Cloud-hosted multimodal video indexing | Prohibitive per-minute cost for smaller platforms and individual creators | Local-first inference inside 16GB RAM, no per-minute cloud bill |
| AWS Rekognition | Cloud-hosted visual recognition and indexing | Same per-minute cost structure; sensitive video must leave the user's infrastructure | Sensitive video never leaves the user's machine |
| ASR-only search (Whisper-style) | Index spoken words inside videos | Captures speech but misses the visual context and the timing between audio and visuals | TMRoPE anchors visual entities to specific audio cues — searchable visual + sound events |
The pipeline anchors visual entities to specific audio cues through time-aligned tokenization, enabling queries like a person jumping paired with a specific sound — a task tag-based systems cannot perform. One-shot prompting on a 7B model also delivers entity-level specificity (e.g., naming a specific public figure) at a fraction of the memory cost of the 70B+ models competitors rely on.
The system.
The platform is a minimal video upload and search application. Users drag-and-drop a short-form clip into a glassmorphism web UI; the FastAPI backend writes a temporary copy, pushes the file to a private Backblaze B2 bucket, and enqueues a job into a Strict Single-Worker FIFO Queue. The queue is load-bearing — running concurrent inferences would crash the PyTorch MPS allocator on the 16GB device the platform targets.
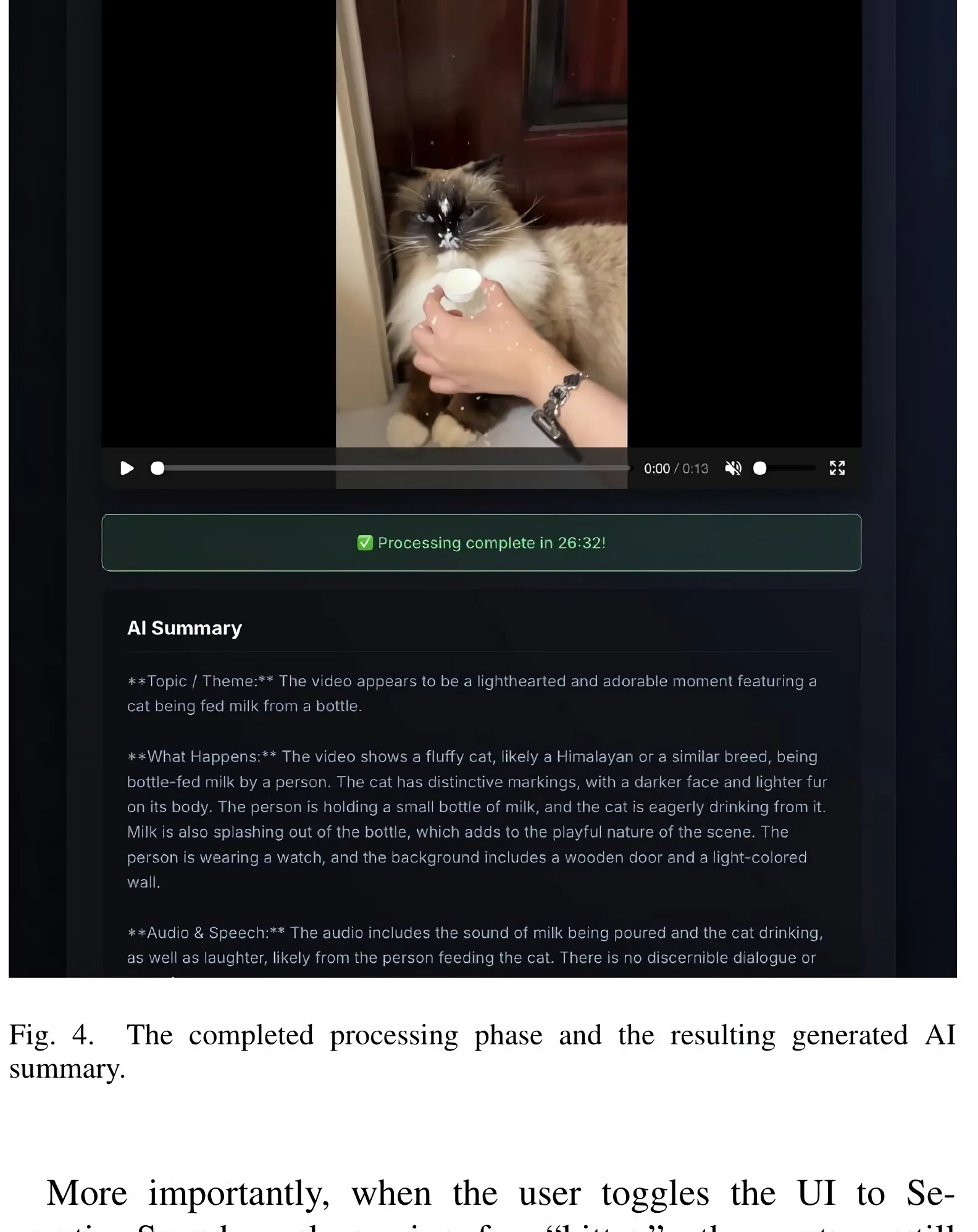
Deep multimodal inference is performed by Qwen2.5-Omni 7B, loaded via Hugging Face transformers and qwen_vl_utils on the Apple-Silicon MPS backend. The model ingests synchronized audio and visual frames in a single pass — no separate speech-to-text or frame-analysis sub-models — and emits a structured textual summary (topic, what happens, audio and speech, tone, key takeaway).
The generated summary is indexed in a Dockerized Elasticsearch 8.13.2 node. The text is also embedded with all-MiniLM-L6-v2 into a 384-dimensional dense_vector, so the search UI can offer both a BM25 keyword mode and a k-NN semantic mode that retrieves videos whose meaning matches the query even when the exact keyword does not appear in the summary.

The implementation.
The pipeline is split across a React + Vite + react-router-dom frontend (glassmorphism UI, dynamic timers, drag-and-drop upload) and an ASGI FastAPI + Uvicorn backend. Videos are uploaded to private Backblaze B2 buckets through boto3 (Signature Version 4), and the backend mints short-lived presigned URLs so the browser can stream the file directly without exposing the bucket.
A major engineering hurdle was getting the 7B model to actually run inside the 16GB target. Native FP16 inference swapped to SSD and pushed latency to 6–8 hours per video. Switching to INT8 via QuantoConfig brought a single video down to 50–60 minutes; pushing further to INT4 cut it to 25–35 minutes without significant semantic degradation.
On the search side, BM25 handles term-frequency / inverse-document-frequency keyword matching, while approximate k-NN with k=5 retrieves the top semantically similar videos. The dual-mode search lets a user query for cat and retrieve the clip with BM25, then re-query for kitten and still retrieve the same clip via the embedding space — proving the semantic pipeline works even when the literal word is absent.

Built with AI.
Where AI helped
- Generated standard web-server logic, boilerplate files, and CSS styling exceptionally fast.
- Drafting the initial Product Requirements Document and parsing it into routed views via Gemini 3.1 Pro.
- Iterative meta-prompting to refine the analyze-page flow into the exact manual-trigger states the team wanted.
Where AI struggled
- Suggested CUDA-only bitsandbytes quantization for an Apple Silicon MPS backend — incompatible and silent.
- Crashed repeatedly on a Python 3.9 types.GenericAlias type-hinting issue inside qwen_vl_utils until the team wrote a manual patch.
- Universally defaulted UI styling to indigo-500 (the Tailwind UI fingerprint) — the team kept the indigo intentionally but acknowledged the bias.
Generative coding tools lack intrinsic awareness of undocumented library bugs or localized hardware limitations; the developer must still enforce physical constraints.
The evidence.
Limits & next.
Limits
- Inference is slow: even at INT4 a single short clip still takes 25–35 minutes on the 16GB target machine.
- The strict single-worker queue serializes uploads — multiple concurrent users would block on each other.
- One-shot prompting works for known entities (e.g., Donald Trump) but requires a hand-curated reference image per recognized figure.
- Pipeline tested on a small dataset of 10–30 second clips; behavior on longer-form video is unverified.
Next
- Batch and parallelize inference across multiple devices to break the single-worker bottleneck.
- Expand the one-shot reference library so the model recognizes a broader set of public figures.
- Extend support beyond 30-second clips toward longer-form video.