
Verified.AI
A GenAI-powered claim-verification workbench combining FAISS dense retrieval, CrossEncoder reranking, and DeBERTa-based natural language inference over Wikipedia evidence.
The rapid spread of misinformation has created a need for fact-checking systems that are both automated and evidence-grounded. Verified.AI is a Retrieval-Augmented Generation (RAG) style claim-verification system that retrieves Wikipedia-based evidence and classifies natural language claims as SUPPORTS, REFUTES, or NOT ENOUGH INFO. Unlike standalone language-model responses, the system emphasizes transparency by returning a predicted label alongside verifier confidence scores and the ranked evidence passages used to support the prediction.
The brief.
Large language models have demonstrated strong performance on many natural language tasks, but they still generate plausible responses that are not fully grounded in verifiable evidence. Search engines and AI-enhanced search tools increasingly surface source-backed summaries, but these systems generally hide the underlying retrieval and ranking decisions from the user. Traditional machine-learning classifiers can predict labels without showing which evidence influenced the decision — neither path lets a reader audit the verdict.
Verified.AI motivates a retrieval-augmented approach where the system first retrieves evidence, then performs evidence-conditioned reasoning, while preserving visibility into each step. The core evaluation uses the FEVER dataset, a benchmark for fact extraction and verification that includes claims, labels, and sentence-level Wikipedia evidence annotations. A targeted Wikipedia subset was constructed from relevant evidence pages, embedded with sentence-transformer models, indexed with FAISS, and evaluated using Recall@K. Retrieved evidence is then reranked with a CrossEncoder and passed into a DeBERTa-based natural language inference verifier.
Target: Students, researchers, journalists, educators, and developers who want to inspect how a claim-verification system retrieves evidence and arrives at a prediction, and to compare how different retrieval, reranking, and verification settings affect the final verdict.
The project demonstrates that retrieval-augmented claim verification can provide a more interpretable alternative to ungrounded generative responses, while also revealing that the main remaining bottleneck lies in verifier reasoning rather than evidence retrieval.From the write-up
The landscape.
| Tool | Approach | Weakness | Our edge |
|---|---|---|---|
| Google AI Overviews | AI-generated summaries with source links | Optimized for broad search; users cannot choose embedding model, adjust retrieval depth, disable reranking, or inspect verifier behavior | Exposes the embedding model, retrieval volume, reranking toggle, and verifier scores as user-adjustable controls |
| ChatGPT / Claude | Conversational AI with optional citations | Reasoning and retrieval pipelines are hidden; user typically sees the final answer rather than full evidence-ranking and verifier-scoring | Shows entailment, neutral, and contradiction scores alongside ranked evidence cards |
| Professional fact-checkers | Human-reviewed verification | Manual workflows that are not designed for interactive experimentation | Programmatic and configurable; designed for studying retrieval-augmented verification rather than replacing it |
| FEVER baseline systems | Benchmark-only research pipelines | Backend models / benchmark systems rather than user-facing educational interfaces | Wraps the pipeline in a workbench UI with settings, analytics, and tutorial pages |
Verified.AI's main differentiator is transparency and configurability. The system gives users control over retrieval settings and exposes the evidence trail behind each prediction. This makes it valuable as a demonstration platform, teaching tool, and foundation for future research into interpretable retrieval-augmented verification — explicitly not a replacement for commercial search or AI assistants.
The system.
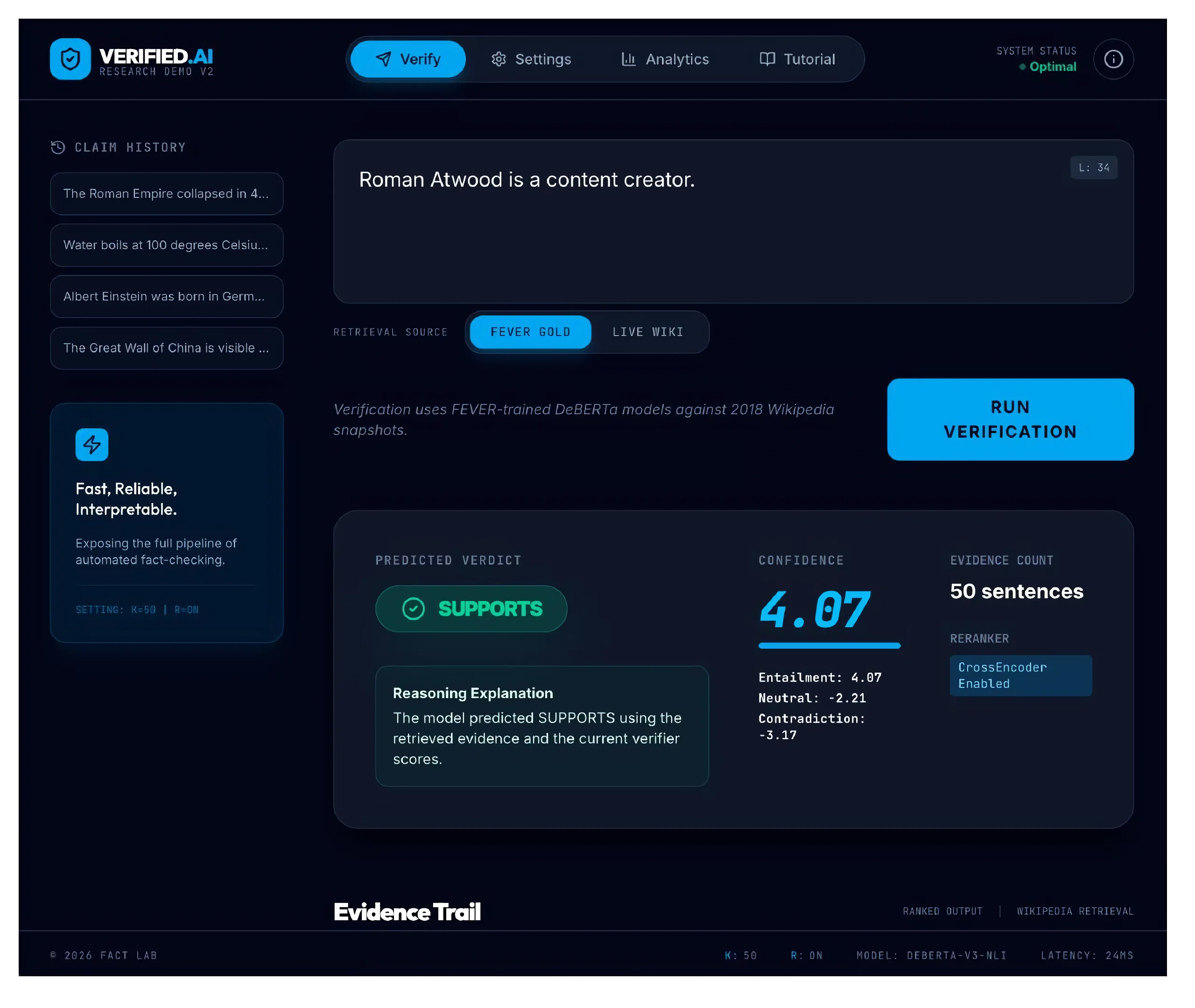
Verified.AI is implemented as an interactive claim-verification workbench. A user enters a natural language claim, chooses a retrieval source, configures retrieval settings, and inspects the evidence used to support the final prediction. The main verification page contains a claim input box, a source toggle, and a verification result panel. Users can choose between FEVER Gold mode (the controlled FEVER-based retrieval pipeline used for evaluation) and Live Wiki mode (an experimental extension that retrieves evidence from current Wikipedia pages using live API requests). The distinction matters: reported quantitative results come from FEVER Gold mode, while Live Wiki mode is intended primarily for interactive demonstration.
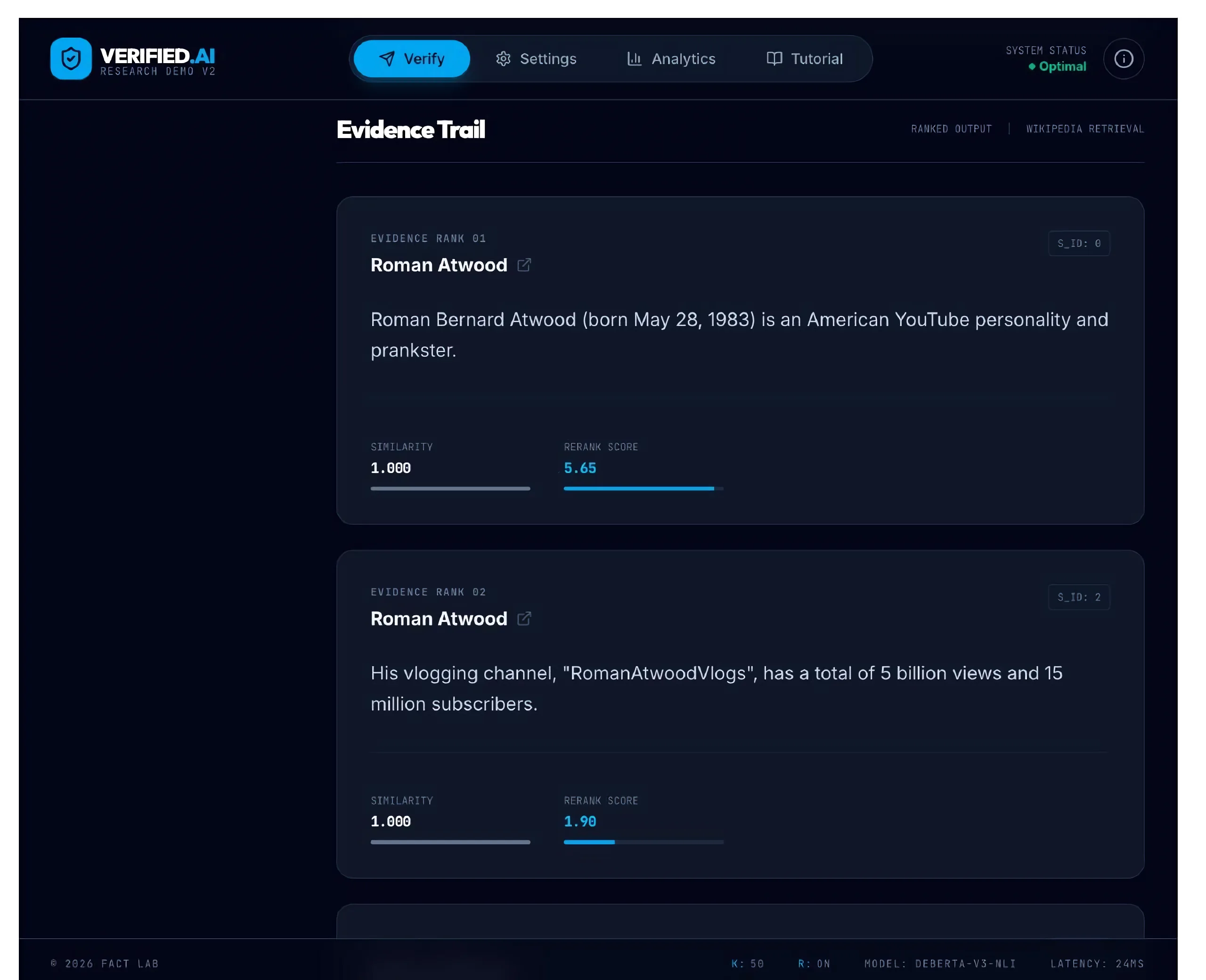
After submission, the system returns a predicted label (SUPPORTS, REFUTES, or NOT ENOUGH INFO) along with a confidence value and verifier scores for entailment, contradiction, and neutral. These help the user see whether the verifier strongly favored one label or whether the decision was uncertain. A central feature of the interface is the evidence trail: retrieved evidence is shown as a ranked list of cards, each including source page, sentence text, similarity score, optional rerank score, and sentence identifier. The user can inspect whether the model relied on meaningful evidence or merely on topically related passages.
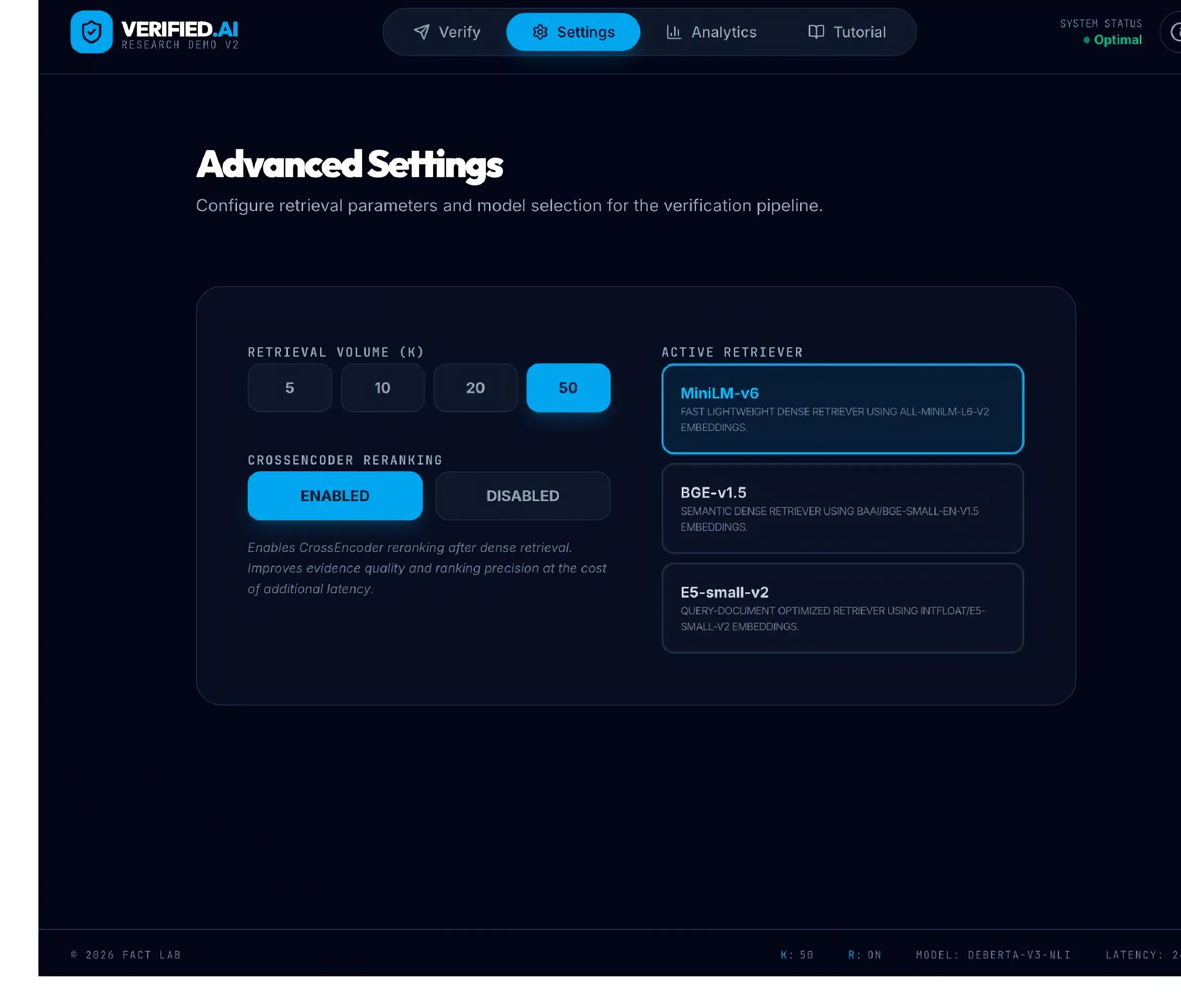
The interface also exposes an Advanced Settings panel (retrieval volume, CrossEncoder reranking toggle, retriever model choice), an analytics dashboard with Recall@1, Recall@5, average pipeline accuracy, NOT ENOUGH INFO rate, and label confidence distributions, and a tutorial page that walks through claim input, dense retrieval, reranking, and verification step by step.
The implementation.
Verified.AI is a modular retrieval-augmented claim-verification system divided into data preprocessing, targeted corpus construction, dense retrieval, reranking, verification, and a UI layer. The FEVER preprocessing step normalizes each JSONL example into a structured (claim, gold label, evidence references) shape; the Wikipedia dump is parsed separately into sentence-level entries keyed by page name and sentence identifier. Because the full FEVER Wikipedia corpus contains over 25 million sentences, the system uses a targeted subset built from pages that appear in the gold evidence annotations of the selected FEVER examples. Reported results use a subset built from the first 100 FEVER examples; after removing examples without usable gold evidence, 75 examples were evaluated.
Evidence sentences are embedded with sentence-transformers/all-MiniLM-L6-v2, converted to float32, normalized with NumPy (faiss.normalize_L2 caused local native crashes on macOS), and stored in a FAISS IndexFlatIP index — inner-product similarity on normalized vectors approximating cosine similarity. The index is saved alongside a metadata file that maps FAISS row IDs back to page name, sentence ID, and sentence text. The backend was also designed to support multiple retriever indexes (MiniLM, BGE, E5); MiniLM is used for the reported evaluation because it was stable throughout development.
Dense retrieval returns a configurable number of candidates (top 50 by default). A CrossEncoder reranks the candidate set: dense retrieval alone achieved Recall@1 of 0.6667 and Recall@5 of 0.9333; reranking lifted Recall@1 to 0.8133 and Recall@5 to 0.9467, while Recall@10 stayed at 0.9733 — confirming that reranking primarily reorders existing gold evidence rather than retrieving new passages. Verification uses a DeBERTa-based CrossEncoder NLI model that ingests retrieved evidence as the premise and the claim as the hypothesis, returning contradiction / entailment / neutral scores mapped to REFUTES / SUPPORTS / NOT ENOUGH INFO. A key implementation decision was splitting the evaluation pipeline into multiple scripts because loading FAISS, SentenceTransformer, the reranker, and the verifier together caused native-library crashes on macOS.
The evidence.
Limits & next.
Limits
- Reported metrics are based on 75 examples with usable gold evidence; broader FEVER evaluation needs full-corpus indexing not feasible on local hardware.
- The full FEVER Wikipedia corpus (~25M sentences) is not indexed locally; results come from a targeted subset built around evaluation pages.
- Live Wiki mode is an experimental extension — reported metrics intentionally exclude it.
- Verifier reasoning, not evidence retrieval, is now the dominant error source: most remaining errors come from the DeBERTa NLI verifier being too conservative or struggling with multi-hop reasoning.
- Native-library crashes on macOS forced a split-pipeline workaround; loading FAISS + SentenceTransformer + reranker + verifier in one process is not stable.
Next
- Replace or augment the DeBERTa NLI verifier with a stronger reasoning model targeting indirect and multi-hop claims.
- Scale the FAISS index toward the full FEVER Wikipedia corpus to remove the targeted-subset assumption.
- Promote Live Wiki mode from experimental to evaluated, with its own held-out benchmark.
- Extend the analytics dashboard with per-retriever and per-verifier ablations so users can compare configurations side by side.
- Add export of evidence trails so external graders can audit individual verdicts.