
BURT++ · Interactive Bug Reporting
A conversational bug-reporting agent that turns vague user descriptions into structured, GUI-graph-grounded reports developers can act on.
Bug reporting often forces non-technical users to describe failures in static forms that provide little guidance and rarely capture the application-specific detail developers need. BURT++ replaces form-based reporting with a conversational agent that combines targeted follow-up questions, application-GUI-graph grounding, and a self-updating internal bug state to map user-supplied information onto concrete screens and interactions. It is implemented as a React + TypeScript frontend, a FastAPI service, Redis-backed sessions, LangGraph orchestration, OpenAI calls, observability logs, and an LLM-as-judge evaluation pipeline.
The brief.
High-quality bug reports are essential for efficient software maintenance, but users often submit reports that are vague, incomplete, or disconnected from the application details developers need. Traditional reporting forms place the full burden on users to know what information matters — observed behavior, expected behavior, and steps to reproduce — and most non-technical reporters cannot reliably supply all three.
BURT++ addresses the gap with a conversational agent that guides users through the reporting process and grounds their answers in a structured GUI graph of the target application. As the conversation progresses, the agent incrementally maps user-provided information to application screens and interactions, then generates a concise final bug report. The project also includes a web interface, backend session API, observability logs, and an evaluation pipeline to support continued development toward a research-ready tool.
Target: Software development teams from startups through enterprise — QA engineers, product managers, and developers who depend on high-quality bug reports — with a focus on SaaS companies that absorb high volumes of low-quality feedback from non-technical end users.
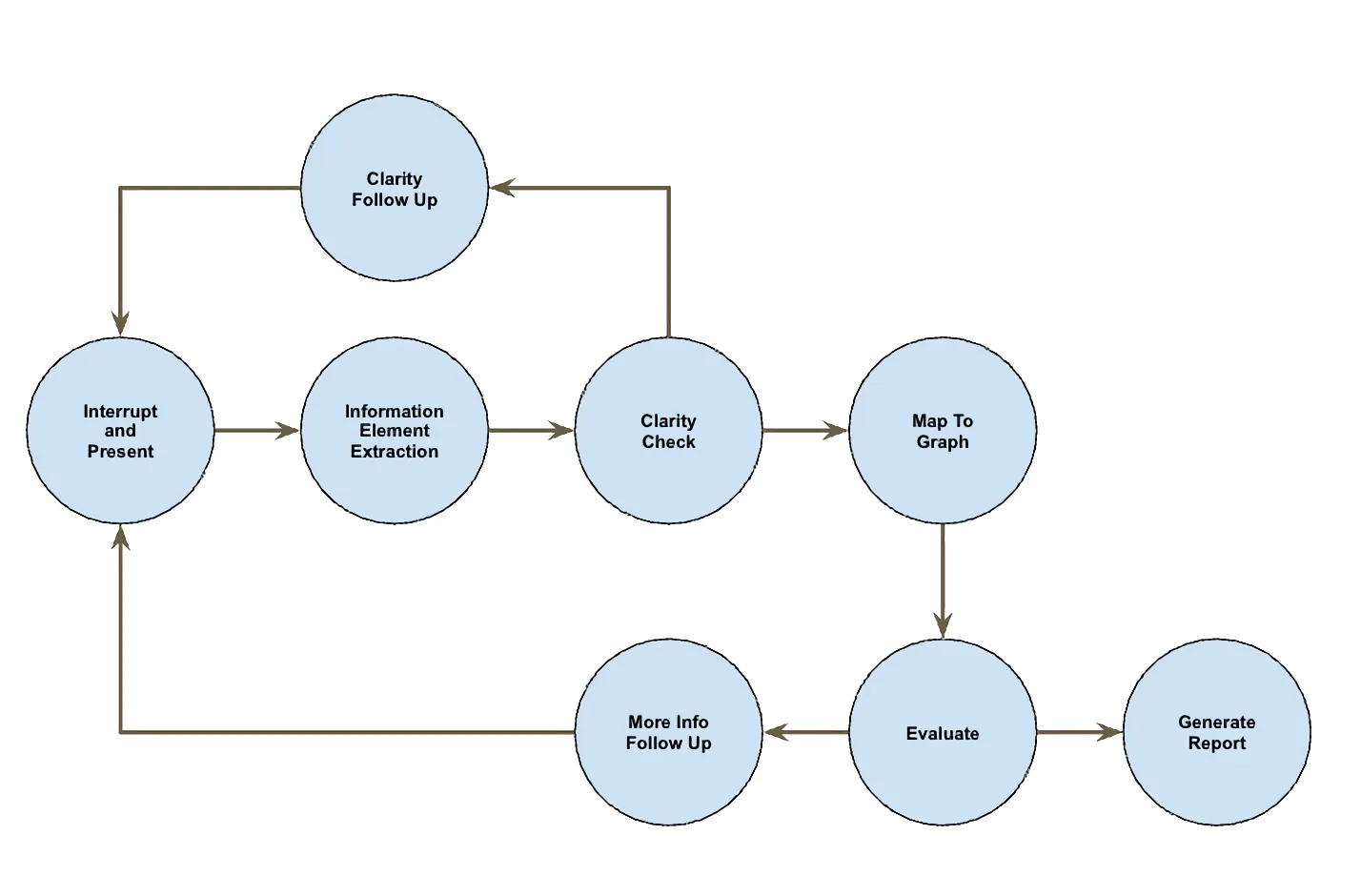
Instead of asking a fixed sequence of questions, BURT++ extracts bug information from each user message, checks whether the information is clear, maps it onto the application GUI graph, and then asks targeted follow-up questions only for missing or ambiguous fields.From the write-up
The landscape.
| Tool | Approach | Weakness | Our edge |
|---|---|---|---|
| Jira / GitHub Issues / Linear | Manual issue tracking with structured forms | Rely entirely on users to input complete and accurate information | Active conversational elicitation, not passive form fields |
| Instabug / Sentry | Feedback SDKs that capture screenshots and logs | Passive — capture context but do not guide users toward higher-quality reports | Adaptive clarification loop that pushes the report toward completeness |
| FeedAIde (arXiv 2603.04244) | Context-aware, LLM-driven follow-up questioning over screenshots and interaction logs | Relatively fixed interaction structure with a limited number of follow-up questions; no application-level reasoning | Grounded in a structured application GUI graph; clarification loop adapts to the specific app, not just the screenshot |
BURT++ grounds user input in a structured GUI graph of the target application — enabling precise mapping of free-text descriptions to screens, actions, and reproducible steps — and runs an adaptive clarification loop that asks follow-up questions only until a complete, developer-ready report can be formed.
The system.
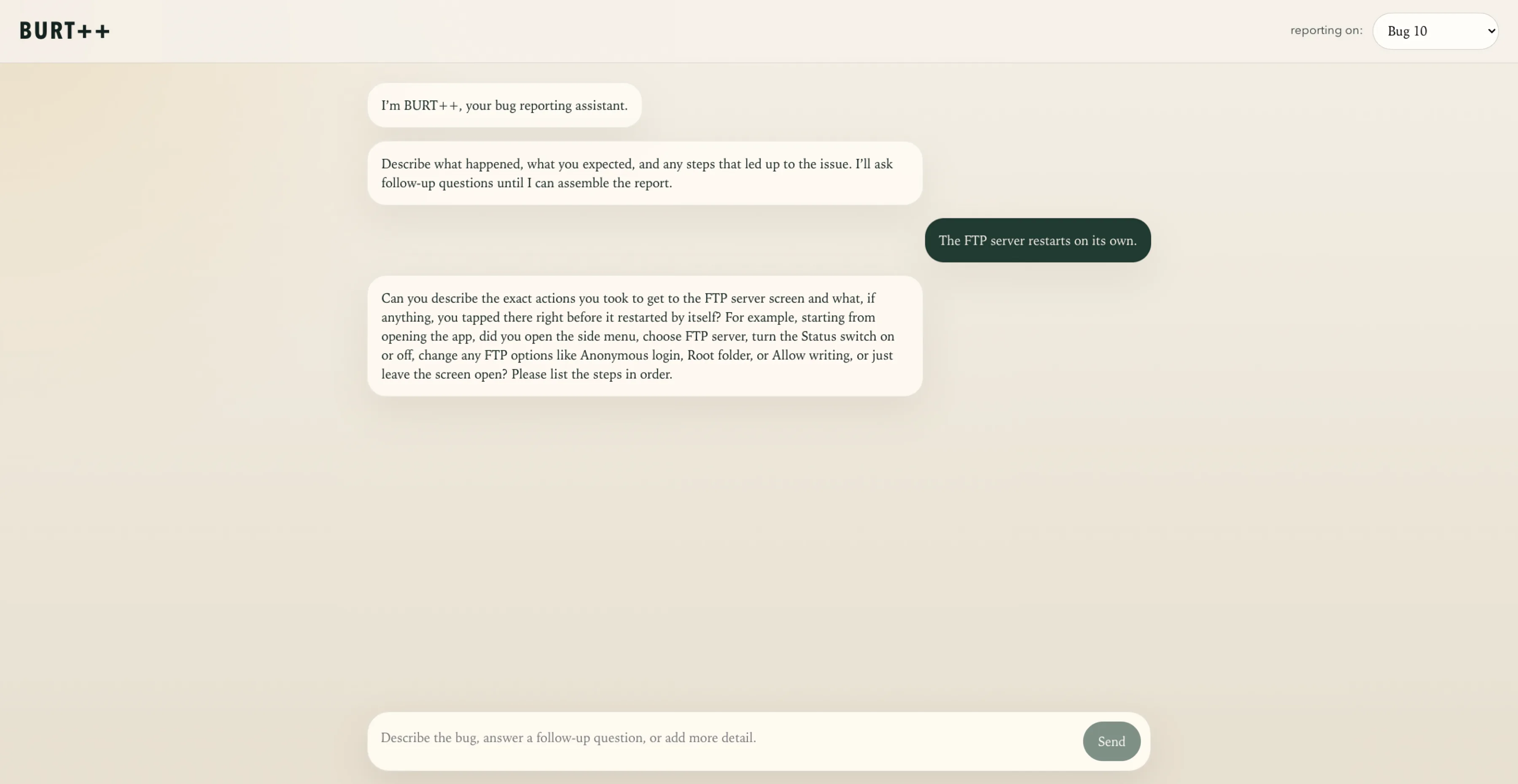
The user begins by selecting a reporting target and entering an initial description in the chat interface. BURT++ then responds in a mixed-initiative style: when the description is already specific enough, it proceeds directly to synthesis; when key details are missing, it asks focused follow-up questions about the triggering interaction, screen context, expected behavior, or reproduction steps.
Internally, the agent maintains a self-updating bug state containing five elements identified by prior work: Buggy Behavior, Correct Behavior, Triggering GUI Interaction, Triggering Screen Reference, and Steps to Reproduce. Each element is tagged with a confidence level — unknown, ambiguous, inferred, or confirmed — and the agent's prompts dispatch on that confidence to decide whether to confirm, refine, or ask.
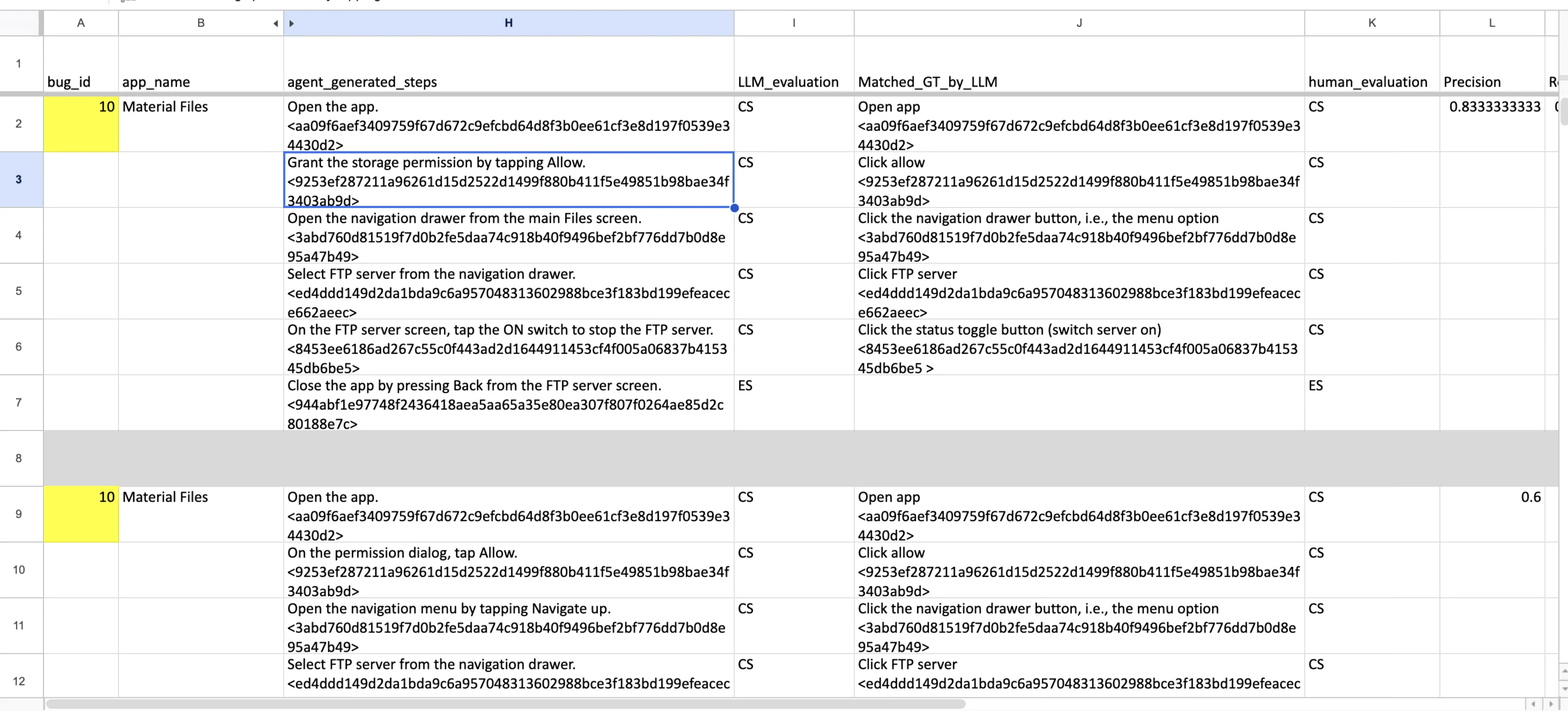
Behind the scenes the system logs every session as a record of turns and agent/user actions, plus latency and token usage. After a run, an evaluator reads the final report, uses an LLM to compare it against development-set reference data, and scores whether the generated report captures the essential information elements and plausible reproduction steps. A manual-review workbook is also produced so automatic scores can be cross-checked by a human.
The implementation.
BURT++ is a split web-and-agent stack. The frontend is a React single-page application written in TypeScript and built with Vite. The backend is a Python FastAPI + Uvicorn service exposing REST endpoints for health checks, active-bug discovery, session creation, session failure recovery, and session resume. The agent itself is orchestrated as a LangGraph state machine with OpenAI GPT-5.4 bindings, Pydantic schemas for typed state and structured outputs, and prompt-versioned runtime logic for information extraction, clarification, graph grounding, and final bug-report generation.
Two use paths are supported. A local quick-dev path runs the agent through a Python CLI with in-memory LangGraph checkpointing and on-disk observability logs. The web path is a small Docker Compose stack of three containers: an Nginx-fronted frontend container, a FastAPI backend container, and a Redis container that handles live session storage, LangGraph checkpointing, and per-session locks for concurrent access control.
The runtime emits observability records that feed the evaluation pipeline. The analysis stack uses openpyxl to generate machine-readable evaluation artifacts plus a manual-review workbook, so the team can run LLM-as-judge scoring at speed while still spot-checking a sample by hand.
Built with AI.
Where AI helped
- Codex planning mode let the team scope every feature down to file and method before any code was written.
- A meta-prompting loop — propose prompt updates, then ask Codex to refine them against the same conversation logs — produced application-grounded prompt optimization.
- Well-maintained README.md and ARCHITECTURE.md files eliminated the 'getting the agent up to speed' phase at the start of every new conversation.
- Frontend (low team expertise area) came up cleanly from one well-crafted planning-mode prompt.
Where AI struggled
- When instructions lacked scope reminders (scalability, final deployment shape) the agent made localized, almost greedy decisions that would have accrued tech debt.
- Required active code review on every artifact to catch prototype-level decisions before they entrenched.
- Considered but did not yet implement an LLM-as-judge code-review pass and a Codex skill with FastAPI/React/Redis best practices to automate that catch.
This was Agent-Driven Development, not Vibe Coding — system design is non-negotiable for a production-level service, even with capable coding agents in the loop.
The evidence.
Limits & next.
Limits
- BURT++ accepts textual input only — a clear weakness against competitors that already support multimodal evidence like screenshots and screen recordings.
- Evaluation still requires manual validation, which scales poorly; the current pipeline also uses a GPT model to evaluate content generated by another GPT model, which does not account for model-family bias.
- The application GUI graph used to ground agent reasoning is static — if the target application evolves, the graph cannot evolve with it.
- Not yet deployed to a public environment; the intended deployment is to run the Compose stack on a SEA Lab machine behind Nginx.
Next
- Add multimodal input: let the agent propose screens or transitions from stored application screenshots and accept file uploads in the user description component.
- Run statistical tests on a paired sample of human-evaluated and LLM-evaluated reports to bound the LLM-as-judge bias, and let the evaluator switch model providers on demand.
- Evolve BURT++ into a multi-agent system where sub-agents continuously maintain the GUI graph the main reporting agent reasons over.
- Conduct a user study on effectiveness and usability, and position a paper for ICSE 2027 submission.